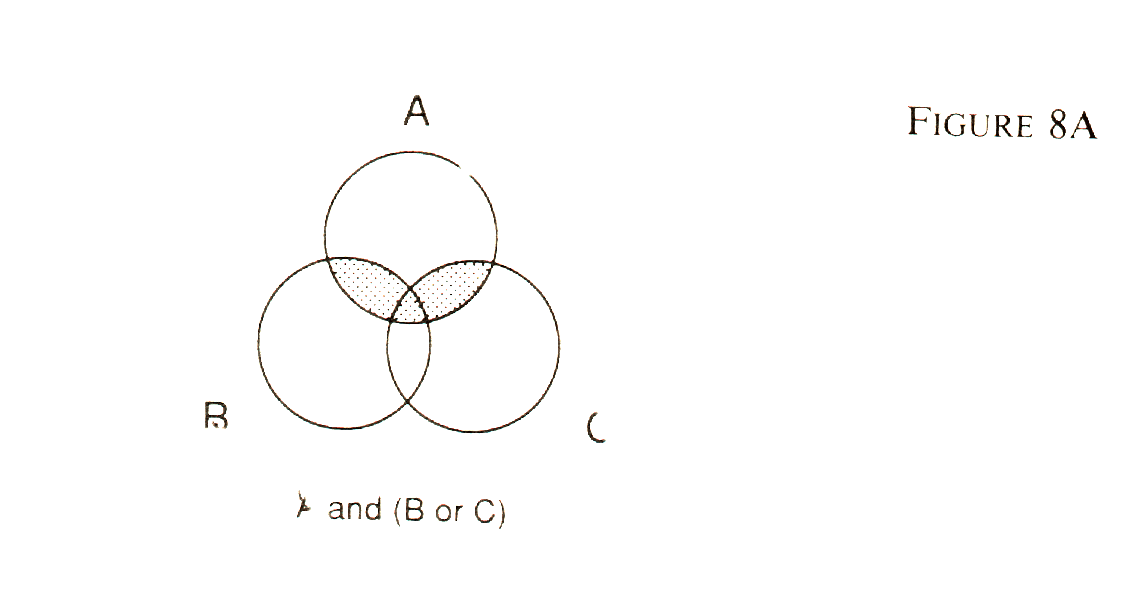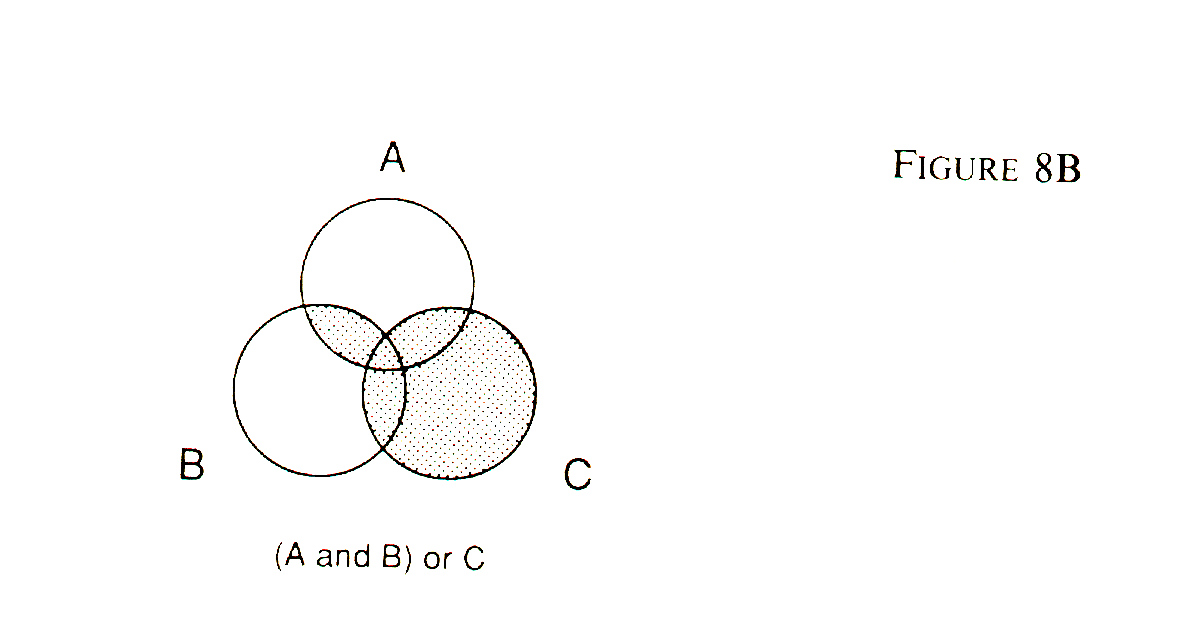The New |
|||||||||||||
Download Chapter 8 |
8
Databases A Miami Herald reporter working a murder story on a Sunday afternoon in April 1990 did the routine things. He interviewed people who knew the dead woman and the man accused of shooting her. He got hints of infidelity and a flamboyant life style. But he needed verification. So he went to Nora M. Paul, director of the Miami Herald library. Here's what she did for him: 1. Using a modem-equipped personal computer, Paul dialed the county's mainframe computer, where Civil Court records were kept, and checked for the victim's name in the index. That yielded the number of a civil case the dead woman had filed against the accused, who, it turned out, was her former boy friend. The case record contained the name of her lawyer. The reporter called him and found out about a criminal case pending against the accused. 2. The woman who answered the accused man's phone refused to give her name to the reporter or to verify that he was married. Paul found the wife's name with a computer query to the Dade County Official Records Index, which produced a mortgage deed listing the couple. 3. A microfiche file in the library contained the registration number of the accused person's car. Paul dialed CompuServe, a national database service for personal computer users, and tapped into its gateway to the Florida Department of Motor Vehicles listings. The DMV record said he drove a 1988 Cadillac. 4. A local real estate database, also accessed by computer, yielded the details on the man's condo: how much he paid for it, how many rooms and baths, total square feet. 5. Using the man's name and current address, Paul dialed into a national credit network and got his social security number, a previous address in New York, and the name of a business he had owned there. 6. From the Miami Herald's own newspaper database, a part of the national Vu/Text service, Paul retrieved a reference to a photo of the accused and the victim attending a fashion show at a local disco. The photo itself was quickly retrieved. The story said the man was called "el conde," Spanish for "count." The six searches just described took less than 20 minutes. The computer charges were less than $20.1 What is going on here? So far in this book, we have considered ways to create your own database, through survey research or field experiments. Now it is time to think about analyzing databases created by somebody else. These archival databases exist in two basic forms: 1. Databases created for public access, usually at a price and with a software system designed to make retrieval fairly easy. These are usually on-line databases kept on large mainframes for remote access, although they are increasingly being made available in transportable form on floppy disks or CD ROMs (compact disks read-only memory) for manipulation on a personal computer. Although in theory these transportable databases could be comprehensive and constantly updated, the agencies that created them had not, by the start of the 1990s, always gotten the hang of keeping them current. They were often incomplete and lagging behind other sources of information. Another source of public access began to develop through PC-based bulletin boards. Government agencies were making increasing use of this tool by 1990. 2. Databases created for a public or private agency's own record-keeping convenience and, usually, without much thought that a journalist would ever be interested in looking at them. To work with these databases, you need to acquire material in off-line form and have the computer skill to interpret it. Fortunately, the same computer skills that you use to analyze public opinion polls can be applied in this area. The principles are the same, but the degree of complexity is different. Both
kinds of database provide considerable opportunity for enterprise reporting.
On-line retrieval In 1989, one researcher counted approximately 4,250 publicly available databases, made accessible through more than 500 gateways or on-line utilities.2 Examples of such gateways are Dialog, BRS, Nexis, and CompuServe. For databases of this kind, a newspaper librarian can be a major resource. A good one will be experienced in using a variety of such sources to gain access to a wide array of government documents, specialized technical publications, newspapers, and magazines. These databases come in two types: full-text and bibliographic. The latter gives a citation and an abstract of an article. The increasing power and decreasing costs of computers will eventually make full-text searching the standard method. You tell the computer what publication or group of publications you want to look in, what time period you want to cover, and what words or phrases you want to search for. You can get back a paragraph, a headline, a lead, or a full article; the choice is yours. The search protocols allow you to specify very complex selection criteria with fairly simple specifications. Using Boolean logic and Venn diagrams, you string together a number of conditions to limit or expand the search. For example, using Knight-Ridder's Vu/Text system, you might ask to see all of the stories in the Miami Herald for 1990 that met one of two conditions: Condition 1: the word "festival" appears. Condition 2: either the phrase "SW 8th St." or "Calle Ocho" appears. The search instruction would look like this: festival and ("Calle Ocho" or "SW 8th St.") Figure 8A shows the Venn diagram for this search, where "A" represents festival, "B" is SW 8th St. and "C" is Calle Ocho.
As in mathematical notation, the expression within the parenthesis is evaluated first. Different retrieval systems have different conventions. Some give priority to "and" while some look first at "or." If you know which is the case with the system you are using, you might not need the parenthesis, but using them will not hurt, and they can keep you from getting confused. Figure 8B shows the Venn diagram for the following variation: (festival and "calle ocho") or "SW 8th St."
Placement of the parenthesis makes quite a difference. In Vu/Text, you can limit your search to a given date or range of dates, and you do global searches of major newspapers or of all newspapers in the system. What if the word you are searching for is not in the story? It is possible, for example, to write a story on arms control that never uses the phrase "arms control." To help you out in such cases, the keepers of electronic libraries often attach key index words to each story to aid in a search. In that way, you can retrieve articles on a given topic with a bit less worry about what exact words would distinguish the stories you want. If a very large number of stories meet the criteria, most systems will warn you before printing them out in order to give you a chance to narrow the search even more. Because these services generally charge according to connect time, you need to give some thought to the structure of each system's retrieval system and learn how to frame your requests to get in and get out with your information without wasting time. That's why a librarian can be helpful. Someone who uses a database on a daily basis will know its nuances better than an infrequent user. However, it is worth your while to learn at least one such database system well. Understanding one will make others easier to grasp as the need for them arises. Some
recent software developments also make retrieval easier. The customary
method in the 1980s was to use a PC as a dumb terminal and depend entirely
on the mainframe software that accompanies the database for the retrieval
operations. But that was a waste of PC capability, and so some clever programmers
started designing PC software that would interact with the mainframe database
software to do the searching efficiently and with a minimum amount of knowledge
on the user's part. Nexis News Plus for personal computers sold for $50
in 1989. It uses pull-down menus and detailed prompts to help you design
your search off-line. Once you have your search organized, this program
dials up the Nexis mainframe for you, conducts the search, and automatically
downloads the results so that you can browse through them at your leisure
and off-line. Similar packages marketed by third-party vendors at higher
cost became available for Dialog and BRS at about the same time.3
Content analysis Retrieval of specific articles is only the beginning of the capacity of these systems. They can also be powerful analytical tools. In the chapter on statistics, you saw how a database search was used to discover the frequency of certain misspelled words in newspapers. Other kinds of content analysis are possible. You can track a social trend, for example, by counting the frequency of words associated with the trend,and watch its movement over time and from one part of the country to another. Public concern with the drug problem, for example, might be tracked just by counting the frequency of the word "cocaine" in newspapers over time. By performing the same analysis for presidential speeches, you could see whether the president's concern preceded or followed the media concern. You could then track public opinion polls, archived in an electronic database by the Roper Center of the University of Connecticut, to see if officials and the media were responding to public concern or whether the public concern was created by the media. For a nice finishing touch, you could look at medical examiner records showing the number of cocaine-related deaths, and determine how far public, media, and official responses all lagged behind the reality of the problem. Knight-Ridder's
Vu/Text system will give you the frequency of stories in which the search
text appears without the need to print out each story. Using that capability,
I was able to track a usage of an old word to form a relatively new cliché
-- the use of the word "arguably" to modify a superlative. It took only
a small expenditure of connect time. I found that newspaper writers in
the east were the first popularizers of the expression but that it gradually
spread west, and that by 1989, the Los Angeles Times had become
the heaviest user in the database. First recorded use in the system was
in a record review by Rich Aregood of the Philadelphia Daily News
in 1978.4
"If you find that I'm also responsible for 'hopefully,'" said Aregood,
"please don't tell me."
The federal government on-line The Government Printing Office is no longer the primary supplier of the most current government information. Data which have time value are now routinely loaded into computers for access by anybody with a PC, a modem, and a communications software package. Some limit access to users who have preregistered. Here are just a few examples of offerings in 1990: Climate Assessment Bulletin Board -- The National Weather Service provides historical meteorological data at the daily, weekly, and monthly level. The Economic Bulletin Board -- The Office of Business Analysis in the U.S. Department of Commerce posts press releases, economic indicators, summaries of economic news, information on obtaining data tapes, and releases from the Bureau of Labor Statistics. Parties
Excluded from Federal Procurement -- The General Services Administration
keeps a list of vendors of various goods and services who have run afoul
of various federal laws and regulations and have been barred from doing
business with the government as a result. Sample causes: violation of pollution
standards, failure to observe equal opportunity rules, violation of previous
government contract. Because the list changes constantly, the computer
is always more up-to-date than the printed reports. The database includes
codes for the cause of the action, the agency that imposed the ban, and
the date it expires.
Off-line databases Your journalistic creativity and initiative can find their fullest expression in the databases that you were never meant to look at. Instead of turning to your library for help, seek out your newspaper's information systems or data processing manager as the person more likely to have the resources you need. You are on less firm ground here. A newspaper librarian is accustomed to helping reporters. An information systems manager serves the business department. Computers were relatively new at newspapers in the 1970s when I first started enlisting the aid of the systems people, and I found them eager to help. It was a way to expand their client base within the company. But when Elliot Jaspin was reporting for the Providence Journal in the 1980s and using the newspaper's computer to retrieve information from computerized public records, the relationship was not as happy. "At the insistence of the Systems Department at my newspaper, I am officially prohibited from taking any computer courses," he said in 1988. "The Systems Department reasoning is that I don't need to know about computers because that is the functioning of the Systems Department."5 Donald B. Almeida, systems director at the Providence Journal, later said there were other issues involved. Jaspin was involved in union activity, and management feared that he would use his computer skills to put out a strike paper. And Jaspin did get help for his reporting projects, according to Almeida. "Elliot did a first-class job, and he did it with first-class support from the Systems Department," he said.6 Whatever the source of conflict, Jaspin left that newspaper for a career of teaching and developing ways to make computerized records more accessible to reporters without relying on help from the business side. Jaspin's efforts led him to a year at the Gannett Center for Media Studies. There he worked on assembling a package of software and hardware that would enable information on a nine-track mainframe tape to be retrieved with a personal computer. The package includes a tabletop tape drive and a menu-driven retrieval system. For reporters to become independently proficient at computer analysis is a sound idea. And it is much easier to do than when all computing was done on expensive mainframes. One of the earliest uses of the computer to analyze public records was a study of the Philadelphia criminal justice system by Donald L. Barlett and James B. Steele of the Philadelphia Inquirer in 1972. They worked from a sample of paper records and hired clerks to transcribe the information into coding forms that could then be converted to a computer medium. For the analysis, I wrote a program for the IBM 7090, a wonderful and busy-looking old mainframe that used 10 refrigerator-size tape drives instead of disk storage. The program was in Data-Text, an early higher-level language developed at Harvard in the previous decade. My goal was to teach the programming technique to one or more members of the Inquirer news staff as we conducted the analysis, so that they could do their own programming for the next project. I failed. Inquirer reporters won many prizes after that, but they did it with shoe leather. The inaccessibility of mainframes at the time -- both physically and conceptually ñ was part of the problem. Today, a bottom-of-the-line personal computer can do everything that the ancient mainframe could do, and a major barrier has been removed. My first involvement with reporters using a high-powered statistical program to analyze public records that had been compiled by a government agency in computer form came in 1978. The reporters were Rich Morin and Fred Tasker of the Miami Herald. By then I was on the corporate staff at Knight-Ridder in Miami, and Louise McReynolds, my research assistant (later a history professor at the University of Hawaii), was the teacher. Morin, Tasker, and McReynolds acquired the tape of tax assessment records from the Dade County assessor's office, mounted it on the Herald's IBM 360 and analyzed it with SPSS. In cases where property had been sold within the previous year, they were able to compare the sale price with the assessed valuation and calculate the degree to which assessed valuation equaled fair market value as required by Florida law. They found that expensive properties were assessed at a much lower ratio to market value than cheaper properties and that business property got a better break than residential property. The tax assessor resigned. When the analysis was repeated the following year, the disparities had been significantly reduced. McReynolds's training mission in Miami, unlike mine in Philadelphia, was a success. Morin went on to study criminal justice records in Monroe County, Florida, and reported that drug-related crimes were dealt with much more leniently than those that were not drug-related. He built a polling operation at the Herald and later went to the Washington Post to direct its polling and database investigations. For sheer intensity in the 1980s, no journalistic database investigator matched Jaspin of Providence. He built a library of data tapes that included
At
Providence, Jaspin's work was based on three fairly simple analytical tools:
simple searches, frequency counts, and list matching. Examples:
Search: The Rhode Island Housing and Mortgage Finance Corporation was created to subsidize home mortgages for low- and middle-income buyers. Jaspin obtained a computer tape with records of 35,000 such mortgages, sorted them by interest rate, and found that loans at the lowest rates, exceptionally low for the time -- 8.5 percent when the market price was 13 to 19 percent -- had been awarded to the sons and daughters of high-ranking state officials. Further investigation revealed that a participating bank ignored rules covering price limits, closing deadlines, and other procedures to aid those well-connected borrowers.8 Frequency count: The state attorney general gave a speech reporting on her two years in office and boasted of a high rate of conviction in cases of murder and welfare fraud. Jaspin used the computer to examine every indictment and to count the convictions and reported that the real conviction rate was much less than she had claimed. In the case of welfare fraud, her conviction rate was "unprecedentedly low."9 Record matching: Jaspin merged two files, the list of traffic violations in Rhode Island and the roster of names of school bus drivers. He discovered that more than one driver in four had at least one motor vehicle violation and that several had felony records, ranging from drug dealing to racketeering.10 Each of these three kinds of computer manipulation is easily within the range of a personal computer database program such as Paradox, PC-File, or dBase. While a great deal can be done with these programs, they are not the most convenient for statistical analysis of the sort done in the Philadelphia criminal justice study or the Dade County tax comparisons. For those databases, the story lay in comparisons of subgroups, which is most conveniently done by: Cross-tabulation: Barlett and Steele, for example, reported that 64 percent of black murder convicts got sentences of more than five years when their victims where white, but only 14 percent got such long sentences if the victims were black. Comparison of means: Property tax fairness can be evaluated by calculating a ratio of sales price to tax valuation, and then finding the mean ratio for different classes of property. For
that kind of number crunching, SAS and SPSS are the software tools of choice.
Both can also do the more elementary things, such as sort and rank-order
cases on given variables and print out lists of the rankings. They also
make it easy to create new variables out of old ones. The ratio of sales
price to tax valuation, for example, is a computer-generated number which
can then be used as input for the next stage of analysis. Even though SPSS
and SAS are conceptually more difficult than the simpler database packages,
they can do more complicated tasks. So, once learned, they are easier to
use for most analytical chores and well worth the effort.
Complex data structures The easiest database to use is one with a simple rectangular file format. A rectangular file, as explained in chapter 5, is one where each case has the same number of records and all the records are the same length. Telling the computer where to look for each record is fairly straightforward. The gradebook for my course on ethics and professional problems is an example of a simple rectangular file. There is one record for each student. Each record contains the student's name, last four digits of the social security number, group identification, project grade, peer rating, midterm grade, book report grade, final examination grade, and course grade. A typical record would look like this: GRIMES 4534 86 102 76 85 90 85 I built the file using a spreadsheet program called SuperCalc4 and then imported it into SAS. The following input statement told SAS how to interpret the numbers from the spreadsheet:
Because
the values are separated by spaces in the raw data, it was not necessary
to tell SAS exactly where to look for them. I just had to give the correct
order. Once the data were in SAS, it was easy to run validity checks, compare
subgroups, test for a normal distribution, and look for natural cutting
points for assignment of the letter grades.
Even large and complicated files can be rectangular. The Bureau of the Census issues a county statistics file that has hundreds of variables for more than three thousand counties and county equivalents in the United States. But it has the same variables for every county, and their relative locations are the same. Here is a portion of the SAS input statement to read that record:
This
statement tells SAS to look in positions 1 through 5 of the first record
in each case to find the county's five-digit Federal Information Processing
Standard code. SEG and TYPE are variables that help identify this particular
record. The county's name is in letters instead of numbers (indicated by
the $ sign) and it is in positions 16 through 45. Median age is in positions
53 through 62, and the computer is told to impute one decimal place, i.e.,
divide whatever number it finds there by 10. Thus a 345 encoded there would
mean the median age was 34.5.
Nonrectangular files A rectangular file is straightforward: a place for everything and everything in its place. Tell the computer where to find things for one case, and it knows where to find them in all. The most common reason for departing from the rectangular form is an unequal number of attributes for each case. For example, in public records of criminal proceedings, a single indictment might cover a number of criminal violations or counts. The number will be different from case to case. You could handle this situation with a rectangular file only by making each record long enough to hold all the information for the longest case. Indictments with fewer counts than the maximum would have blank spaces in the record. We organized the Barlett-Steel criminal justice data in that way in order to maintain the simplicity of a rectangular file. Another way to organize such a file would be to put all the identifying information -- name of defendant, arresting officer, date, location of crime, etc. -- on the first record along with the first count of the indictment. The second record would repeat the identifying information and then give the data on the second count. Each case would have as many records as there are counts in the indictment. With
such a file, you would be free either to make the indictment the unit of
analysis or you could treat each count as a separate unit. Either SAS or
SPSS can easily handle the problem of unequal record lengths or unequal
number of records per case.
Hierarchical or nested files The problem with the arrangement just described is that it wastes space. The key information about each indictment has to be repeated for each count of the indictment. How much simpler it would be if the basic information about the defendant and the indictment could be given only once and the counts for that indictment then listed one after another. That kind of nesting is handled easily by either SAS or SPSS. Either system allows you to spread that basic information at the top of the hierarchy to all of the elements at the level below. An SPSS manual gives the clearest illustration of a nested file that I have ever seen in print.11 Imagine a file that records motor vehicle accidents. The basic unit of analysis (or observation) is an accident. Each accident can involve any number of vehicles, and each vehicle can contain any number of persons. You want to be able to generalize to accidents, to vehicles involved in accidents, or to people in vehicles involved in accidents. Each
case would have one record with general information about the accident,
one record for each vehicle, and one record for each person. The total
number of records for each case will vary depending on how many vehicles
were involved and how many persons were in those vehicles. The organization
scheme for the first case might look like this:
This
would be a two-vehicle accident with one person in the first vehicle and
two persons in the second vehicle. There would be a different format for
each record type. Record type 1, for example, would give the time, place,
weather conditions, and nature of the accident and the name of the investigating
officer. Record type 2 would give the make and model of the car and extent
of the damage. Record type 3 would give the age and gender of each person
and tell whether or not he or she was driving and describe any injuries
and what criminal charges were filed if any.
In
analyzing such a data set, you can use persons, vehicles, or accidents
as the unit of analysis and spread information from one level of hierarchy
to another. SAS or SPSS are the easiest programs to use for such complex
data sets.
Aggregate v. individual data In the examples just cited, the data provided information down to the individual person or incident. In many large government databases, the volume of information is so great that only aggregates of information are generally made available. The United States Census, for example, releases data in which various geographical divisions are the observations or units of analysis. The data further divide those geographical units into various demographic categories -- age, race, and gender, for example -- and tell you the number of people in various categories and combinations of variables, but they never let you see all the way down to one person. For that reason, you can't do cross-tabulation in the sense that was described in the previous chapter. But you can produce original analysis by aggregating the small cells into bigger ones that make more sense in testing some hypothesis. A good example of a hierarchical file that uses aggregate data is the database version of the FBI Uniform Crime Reports. This database is a compilation of month-by-month reports of arrests from thousands of local law enforcement agencies. One of its files, released in 1989, was called the AS&R (for age, sex, and race) Master File, 1980 ñ present. It was a nested file with three levels. The first record type was called the "agency header," and its unit of analysis was the reporting police department or other agency. It contained just nine variables, including state, county, metropolitan area (if any), name of the law enforcement agency, the population size of its jurisdiction, and the year. The second record type was called the "monthly header." Its unit of analysis was the month. There was one such record for each month covered in the data to follow. Naturally, the data on this record listed the month and the date that the information was compiled. The third level of the hierarchy contained the substantive information. Its unit of analysis was the type of offense: e.g., "sale or manufacture of cocaine." For each offense, there was a 249-byte record that gave the number of arrests in each of up to 56 demographic cells. These cells included: Age by sex, with two categories of sex and twenty-two categories of age or forty-four cells in all. Age by race, with two categories of age and four categories of race or eight cells. Age by ethnic origin (Hispanic and non-Hispanic), with two categories of age and two of ethnic origin for a total of four cells. Because the individual data are lost in this compilation, you might think there is not much to do in the way of analysis. It might seem that all you can do is dump the existing tabulations and look at them. But it turns out that there is quite a bit you can do. Because the data are broken down so finely, there are endless ways to recombine them by combining many small cells into a few big ones that will give you interesting comparisons. For example, you could combine all of the cells describing cocaine arrests at the third level of the hierarchy and then break them down by year and size of place, described in the first record at the top of the hierarchy. Shawn McIntosh of USA Today did that using the SAS Report function and found a newsworthy pattern: cocaine arrests were spreading across the country from the large metropolitan jurisdictions to the smaller rural ones as the cocaine traffickers organized their distribution system to reach the remoter and unsaturated markets. She also found a trend across time of an increase in the proportion of juveniles arrested for the sale or manufacture of cocaine. With
those patterns established, it became a fairly simple matter to use SAS
to search for interesting illustrations of each pattern: small jurisdictions
with large increases in cocaine arrests; and jurisdictions of any size
with a sudden increase in juvenile dope dealers. Once identified, those
places could be investigated by conventional shoe-leather reporting.
The dirty-data problem The larger and more complex a database becomes, the greater the chances of incomplete or bad data. The 1988 Uniform Crime Reports showed a big drop in all types of crime in the southeastern region. A second look revealed that Florida was missing from the database. The state was changing its reporting methods and just dropped out of the FBI reports for that year. A database reporter needs to check and double check and not be awed by what the computer provides just because it comes from a computer. In evaluating the information in a database, you always need to ask who supplied the original data and when and how they did it. Many government databases, like the Uniform Crime Reports, are compilations of material gathered from a very large number of individuals whose reliability and punctuality are not uniform. The United States Environmental Protection Agency keeps a database of toxic waste emissions. The information is collected from industry under Section 313 of the Emergency Planning and Community Right-to-Know Act. Each factory is supposed to file a yearly report by filling out EPA Form R. Data from that paper form are then entered into the database, which becomes a public document available on nine-track tape. It is a complex hierarchical file which shows each toxic chemical released and whether the release was into air, water, or land and whether the waste was treated, and, if so, the efficiency of the treatment. The information went into the database just the way the companies supplied it. The database was too large for any available personal computer in 1989, so a USA Today team led by Larry Sanders read it using SAS on an IBM mainframe. One of the many stories that resulted was about the high level of damage done to the earth's ozone layer by industries that the public perceives as relatively clean: electronics, computers, and telecommunications. They were the source of a large share of the Freon 113, carbon tetrachloride, and methyl chloroform dumped into the environment. The SAS program made it relatively easy to add up the total pounds of each of the three ozone-destroying chemicals emitted by each of more than 75,000 factories that reported. Then the SAS program was used to rank them so that USA Today could print its list of the ten worse ozone destroyers. What happened next is instructive. Instead of taking the computerized public record at face value, USA Today checked. Carol Knopes of the special projects staff called each installation on the dirtiest-ten list and asked about the three chemicals. Eight of the ten factories verified the amount in the computer record. One of the companies, Rheem Manufacturing Co. of Fort Smith, Arkansas, a maker of heating and air conditioning equipment, did release some Freon 113, but the company had gotten its units of measurement mixed up, reporting volume instead of weight. It had filed an amended report with EPA showing a much lower number, and so it came off the list.12 A similar clerical error was claimed by another company, Allsteel Inc. of Aurora, Illinois, but it had not filed a correction with EPA. Because USA Today's report was based on what the government record showed, the newspaper kept Allsteel on the list, ranking it fifth with 1,337,579 pounds but added this footnote: "Company says it erred in EPA filing and actual number is 142,800 pounds."13 As a general rule, the larger the database and the more diverse and distant the individuals or institutions that supply the raw information, the greater the likelihood of error or incomplete reporting. Therefore database investigations should follow this rule:
Naturally,
you can't check every fact that the computer gives you. But you can check
enough of a representative sampling to assure yourself that both the data
and your manipulation of them are sound. And where portions of the data
are singled out for special emphasis, as in the dirty-ten list, you can
and should check every key fact.
The United States census One government database that is both extremely large and reasonably clean is the report of the U.S. Census. The census is the only data collection operation mandated by the Constitution of the United States: ". . . enumeration shall be made within three years after the first meeting of the Congress of the United States, and within every subsequent term of ten years, in such manner as they shall by law direct."14 The first census was in 1790, and its data, like those of later censuses, are still readily available in printed form.15 In 1965, for the first time, the Bureau of the Census began selling data from the 1960 census on computer tape. That proved a popular move, and the tape publication was expanded in later censuses as users gained in computing capacity. The printed publications are still issued, but the computer versions generally come first, and news media that do not want to take a chance of being beaten need to acquire the skills to read and analyze those tapes. Fortunately, it keeps getting easier. Most of the tapes are in summary form. Like the Uniform Crime Report tapes described earlier in this chapter, they give no data on individuals, just the total number of individuals in each of a great number of geographic and demographic cells. The analytical tools available, therefore, are generally limited to the following: 1. Search and retrieval. For example, a crime occurs in your town that appears to be racially motivated. If you have the right census tape at hand, you can isolate the blocks that define the neighborhood in which the crime occurred and examine their racial composition and other demographic characteristics. 2. Aggregating cells to create relevant cross-tabulations. You are limited in this endeavor to whatever categories the census gives you. They are, however, fairly fine-grained and a great deal can be learned by collapsing cells to create larger categories that illuminate your story. For example, you could build tables that would compare the rate of home ownership among different racial and ethnic groups in different sections of your city. 3. Aggregate-level analysis. The 1990 census, for the first time, divides the entire United States into city blocks and their equivalents so that even the remotest sheepherder's cabin is in a census-defined block. That gives the analyst the opportunity to classify each block along a great variety of dimensions and look for comparisons. For example, you could compare the percent of female-headed households with the percent of families with incomes below a certain level. That could tell you that areas with a lot of poor people also have a lot of female-headed families. Because this analysis only looks at the aggregates, it is not in itself proof that it is the female-headed households that are poor. But it is at least a clue. Aggregate
analysis is most useful when the aggregate itself, i.e., the block or other
small geographic division, is as interesting as the individuals that compose
that aggregate. Example: congressional redistricting has carved a new district
in your area. By first matching blocks to voting precincts, you can use
aggregate analysis to see what demographic characteristics of a precinct
correlate with certain voting outcomes.
The public-use sample There is one glorious exception to all of these constraints involving aggregate data. The census publishes two data files that contain data on individuals, so that you can do individual-level correlations and cross-tabulations to your heart's content. These files each contain a sample of individual records, with names and addresses eliminated and the geographical identifiers made so general that there is no possibility of recognizing any person. One file contains a one-percent sample, and one is a five-percent sample, and they can be analyzed just like survey data as described in the previous chapter. The potential for scooping the census on its own data is very rich here, especially when breaking news suggests some new way of looking at the data that no one had thought of before. The
bad news about the public-use sample is that it is close to the last data
file to be published. Typically it shows up about two years after the year
in which the census was taken. By that time journalists covering the census
are tired of it and may have prematurely convinced themselves that they
have squeezed all the good data out already. And if that is not the case,
the two-year lag makes it hard to convince oneself that the data are still
fresh enough to be interesting. But they are. As late as 1989, sociologists
were still finding out interesting things about race and employment from
the 1980 public-use sample.
New computer media The standard medium for census releases in the 1990s was still the nine-track computer tape. However, the availability of nine-track tape drives for personal computers puts that material more within the reach of a well-equipped newsroom. And the census began experimenting with some newer media forms. Starting in 1984, the Bureau of the Census created its own on-line information service, made available through the Dialog and CompuServe gateways. This database, called CENDATA, has two missions: to keep users advised of new data products, and to store interesting subsets of the 1990 data for direct access. The 1990 census was the first for release of data on CD-ROM. Because one of those disks, the same size that provides music for your living room, can hold as much data as 1,500 floppy diskettes, their potential is great. However, for the 1990 census, their delivery was given a lower priority than data in the venerable tape format. Some
investigative and analytical tasks with census data will be well within
the scope of the small personal computer, and so the census planned to
release a few small summary files on floppy diskettes. The bureau's enthusiasm
for this particular medium was not great. However, a reporter wanting to
work with data in that form can abstract a subset from a tape release and
have it downloaded to PC format. A number of computer service bureaus that
specialize in census data can also do it. State data centers and university
research centers are other potential sources.
Geographic structure of the census Census files are nested files. Each follows all or a portion of the same hierarchy. To interpret a census file, you should have either a custom-designed census analysis program or a general statistical program, such as SAS or SPSS, that provides for spreading the information on hierarchical files. This is the hierarchy of the census:
In
older parts of the United States, a block is easily defined as an area
surrounded by four streets. The blocks of my youth were all rectangular,
and they all had alleys. Today, many people live in housing clusters, on
culs-de-sac, on dead-end roads, and at other places where a block would
be hard to define. The census folks have defined one where you and everyone
else lives anyway. A block is now "an area bounded on all sides by visible
features such as streets, roads, streams, and railroad tracks, and occasionally
by nonvisible boundaries such as city, town, or county limits, property
lines, and short imaginary extensions of streets." And, for the first time
in 1990, the entire United States and Puerto Rico were divided into blocks
-- 7.5 million of them.
Blocks fit snugly into block groups without crossing block group lines. And block groups are nested with equal neatness and consistency into census tracts. At the tract level, you have a good chance of making comparisons with earlier census counts, because these divisions are designed to be relatively permanent. They have been designed to hold established neighborhoods or relatively similar populations of 2,500 to 8,000 persons each. Not all of the United States has been tracted. You will find census tracts in all of the metropolitan statistical areas and in many nonmetropolitan counties. Areas that do not have tracts will have block numbering areas (BNA) instead, and you can treat them as the equivalent of tracts for the sake of completeness, but they may not have the same homogeneity or compactness. Neither tracts nor BNAs cross county lines. Counties, of course, do not cross state lines, and the census regions and regional divisions are designed to conform to state lines. So here you have a hierarchy where the categories are clear and consistent. From block to block group to tract or BNA to county to state to division to region, the divisons are direct and uncomplicated. Each block is in only one block group, each block group is completely contained within only one tract or BNA. But the true geography of the United States is a little more complex, and the remaining census divisions were created to allow for that. For one thing, cities in many states are allowed to cross county lines. Other kinds of divisions, such as townships or boroughs, can sometimes overlap with one another. Because such places are familiar, have legal status, and are intuitively more important than collections of blocks that statisticians make up for their own convenience, the census also recognizes these kinds of places. A "place" in the census geographical hierarchy can be an incorporated town or city or it can be a statistical area that deserves its own statistics simply because it is densely populated and has a local identity and a name that people recognize. What
happens when a census "place" crosses a county line or another of the more
neatly nested categories? The data tapes give counts for the part of one
level of the hierarchy that lies within another. For example, in the census
file for the state of Missouri you will find data for Audrian County. Within
the county are counts for Wilson Township. No problem. All of Wilson Township
falls within Audrian County. The next level down is the city of Centralia,
and now it gets complicated, because only part of the city is within Audrian
County. For the rest of Centralia you will have to look in Boone County.
The tape uses numerical summary-level codes to enable the user to link
these patchwork places into wholes. For stories of local interest you will
want to do that. It will also be necessary when there is a need to compare
places that are commonly recognized and in the news. But for statewide
summaries, the work will be much easier if you stick to geographic categories
that are cleanly nested without overlap: counties, tracts, block groups,
and blocks.
Timing of the census Computer tapes are easier to compile than printed reports. So the tapes generally appear first. The exception is the very first release, the constitutionally mandated counts for the apportionment of the House of Representatives. The president gets the state population counts by the end of the census year. Those counts determine how many representatives each state will have in the next Congress. Next, under Public Law 94-171, each state gets detailed counts for small geographic areas to use in setting the boundary lines for congressional districts. These districts are supposed to be compact, contiguous, and reasonably close in population size. So that state legislatures can take race and ethnicity into account, these reports include breakdowns by racial category, Hispanic origin, and age grouping. Because legislatures are starting to use computers to do their redistricting, the data are delivered on tape and CD-ROM at about the same time. Deadline for these materials is the first of April in the year after the census. When all goes well, it arrives earlier. As soon as the Bureau of the Census has fulfilled its legal obligation to the states with the delivery of these data, the PL 94-171 tapes, listings, and maps become available to the public. While the PL 94-171 tapes are the sketchiest in terms of solid information, their timeliness makes them newsworthy. The obvious story is in the possibilities for redistricting, and in the ethnic and age composition of the voting-age population within the district boundaries being considered. Another obvious story opportunity is the growth of the Hispanic population. Although Hispanics have been an important part of the U.S. population since the 1848 cession of the Mexican territory, the census has been slow to develop a consistent method of enumerating it. The 1970 census was the first to base Hispanic classification on a person's self-definition. Before that, it relied on secondary indictors such as a Spanish surname or foreign language spoken. But the growth and movement of the Hispanic population since 1970 is an ongoing story. County boundaries seldom change from one census to another, so a comparison from ten years previously can show the relative magnitude of Hispanic gains in different parts of the country. For local stories, the availability of the counts at the block level allows precise identification of the Hispanicneighborhoods. Growth or decline of different racial groups will also be newsworthy in some areas. The census data get better and better as time goes by. The problem is that they also get older. By the time the really interesting material is available, the census is several years old, and readers and editors alike may be tired of reading about it. The trick in covering it is to plan ahead so that the minute a new tape becomes available you can attack it with a pre-written program and a well-thought-out strategy for analysis. After
the apportionment materials, the STF series (for Summary Tape Files) are
released. The simplest data come first.
Content of the census To reduce the burden on respondents, the census relies on sampling. A limited number of questions is asked of all known households and residential institutions (e.g., college dormitories, military installations, ships in harbors). Additional questions are asked of a 17-percent sample. The advantage of the short form is that its information can be released quickly and is generalizable down to the smallest blocks. The disadvantage is that the information is sketchy: the population data includes the relationship of each person in the household and each person's sex, race, age, marital status, and whether he or she is of Hispanic origin. In addition, there are some housing items: number of units in the structure, number of rooms in the unit, whether the place is owned or rented, its value (if owned) or the amount of monthly rent, whether meals are included in the rent, and, if the unit happens to be vacant, the reasons for the vacancy and the length of time it has been vacant. Getting out this brief amount of data can take up to two years after the census. It comes in a series of files of increasing complexity and geographic detail. It takes about three years to get the bulk of the sample data flowing, although the Bureau of the Census keeps trying to use improved technology to step up the pace. It is worth waiting for. The information includes: Detailed educational attainment. The 1990 census asks for the highest degree a person has earned rather than the number of years of school. While providing greater accuracy, it makes the question only roughly comparable with earlier censuses. Ancestral origin. In addition to Hispanic and non-Hispanic, some really detailed categories become available, such as Mexican, Croatian, or Nigerian. Residence five years ago. This is a staple of the census and provides a good indicator of population mobility. Military service. Using the public-use sample, which provides individual data, you can find out how Vietnam veterans were faring in 1990 compared to nonveterans of similar background. Disability. Helps keep track of an increasingly assertive interest group. Groups whose problems can be quantified have a better chance of getting the government to pay attention to them. So advocates for the disabled won a major victory in the 1990 census by getting a count of those who have difficulty taking care of themselves or getting from place to place.16 Employment status. Stories on the changing composition of the work force will come from this question. Commuting. The method of getting to work and the time it takes are asked about. New in 1990: at what time of day does a person leave for work? Newspaper circulation managers should be interested in that question. Income. Compare with earlier census to see what parts of your area are gaining the most and which are relative losers. Remember
that, except for the late-arriving public-use sample, all of this information
is reported in aggregates: the numbers in cells of various combinations
of geography and demography. The most interesting analysis is done by combining
those cells into forms that will reveal interesting things about your community
or test interesting hypotheses. The SAS procedure PROC SUMMARY or the SPSS
procedure AGGREGATE can do the job nicely. And both systems have report
generators that will print out slick looking tables that show at a glance
how your hypothesis is faring.
Analysis of data from multiple sources Information from the census is seldom as interesting in isolation as it is when compared with information from other sources. Election returns offer one obvious source, but there are many others, depending on how the news breaks. For example, a reporter could combine census data with real estate tax records to test the conventional belief that real estate values drop when a neighborhood changes from white to black. Juanita Greene of the Miami Herald looked at the history of real estate transactions in her town and found that prices in the long run tended to rise as much in changing neighborhoods as in those that remained all white.17 It was not a surprising finding to social scientists who had done research on the same subject in the same way.18 But it was surprising to Miami newspaper readers. And these readers would not have been convinced that their intuitive beliefs were wrong by reading a social science treatise. To convince Miami readers, you have to give them Miami addresses, Miami dates, and Miami prices as Greene did. One of the issues during the war in Vietnam was the fairness of the draft. President Johnson, in order to minimize public opposition to the war, oversaw a selection system that was biased toward the powerless. The educational deferment was the chief mechanism, but not the only one. The smart and the well-connected knew how to get into a reserve unit, how to qualify for conscientious objector status, or, as a last resort, how to get out of the country. This state of affairs reached public awareness only dimly. The Washington Post shed some light in 1970 when it correlated socioeconomic status of neighborhoods with their contributions of military manpower. The inner-city black neighborhoods sent far more of their young men off to war than did the upscale neighborhoods of Georgetown and Cleveland Park. Such a situation is more believable when you can put a number to it. Bill Dedman of the Atlanta Constitution won the 1989 Pulitzer Prize for investigative reporting with an overlay of census figures on race and federally mandated bank reports on home loans. The guts of his series was in a single quantitative comparison: the rate of loans was five times as high for middle-income white neighborhoods as it was for carefully matched middle-income black neighborhoods. One number does not a story make, and Dedman backed up the finding with plenty of old-fashioned leg work. His stories provided a good mix of general data and specific examples, such as the affluent black educator who had to try three banks and endure insulting remarks about his neighborhood before getting his home improvement loan. One of the most telling illustrations was a pair of maps of the Atlanta metropolitan area. One showed the areas that were 50 percent black or more in the 1980 census. The other showed the areas where fewer than 10 percent of owner-occupied homes were financed with loans from banks or savings and loan associations. The two patterns were a near perfect match.19 Dedman had help. In evaluating the evidence of racial prejudice on the part of banks, he followed a methodological trail that had been established by university researchers. Dwight Morris, the assistant managing editor for special projects, supervised the computer analysis. No complicated mainframe or sophisticated statistical analysis package was needed. The job was done with Framework, an Ashton-Tate product that integrates basic word processing, database management, spreadsheet, communication, and graphics software. There
are a lot of good, complicated stories behind simple numbers. The trick
is to identify the number that will tell the story and then go find it.
The new tools for manipulating data in public records should make it easier
for journalists to find and reveal such light-giving numbers.
Notes 1. Nora Paul, "For the Record: Information on Individuals," Database, April 1991. return to text 2. Russ Lockwood, "On-line Finds," Personal Computing, December 1989, p. 79. return to text 3. "Self-searching Databases," Personal Computing, December 1989, p. 83. return to text 4. Philip Meyer, "Trailing a Weasel Word," Columbia Journalism Review, Jan.-Feb. 1990, p. 10. return to text 5. Elliot Jaspin, "Computer = reporting tool," in The Computer Connection: A Report on Using the Computer to Teach Mass Communications (Syracuse University 1989), p. 21. return to text 6. Donald B. Almeida, telephone interview, October 10, 1990. return to text 7. Jaspin, "Computer = reporting tool." return to text 8. "Sons, daughters of state leaders got 8½ percent RIHMFC loans," Providence Journal, June 2, 1985, p. 2. return to text 9. Jaspin, "Computer = reporting tool," p. 19. return to text 10. "R.I. system fails to fully check driving records of bus applicants," Providence Sunday Journal, March 1, 1987, p. 1. return to text 11. SPSS X Users Guide (New York: McGraw-Hill, Inc., 1983), p. 171. return to text 12. Interview with Carol Knopes, November 21, 1989. return to text 13. "Plants sending out most CFCs," USA Today, July 13, 1989. return to text 14. The Constitution, Article I, Section II, Paragraph 3. return to text 15. U.S. Bureau of the Census, Historical Statistics of the United States, Colonial Times to 1970, Bi-Centennial Edition (Washington: U.S. Government Printing Office, 1975), two volumes. return to text 16. Felicity Barringer, "Scrambling to Be Counted in Census," New York Times, December 3, 1989, p. 18. return to text 17. Miami Herald, November 22, 1964. return to text 18. Davis McEntire, Residence and Race (Berkeley: University of California Press, 1960). return to text 19. Bill Dedman, "Atlanta blacks losing in home loans scramble," The Atlanta Journal-Constitution, May 1, 1988, p. 1. The series has been reprinted under the title "The Color of Money" by the Journal-Constitution Marketing Department. return to text |
||||||||||||
Download Chapter 8 |
|||||||||||||